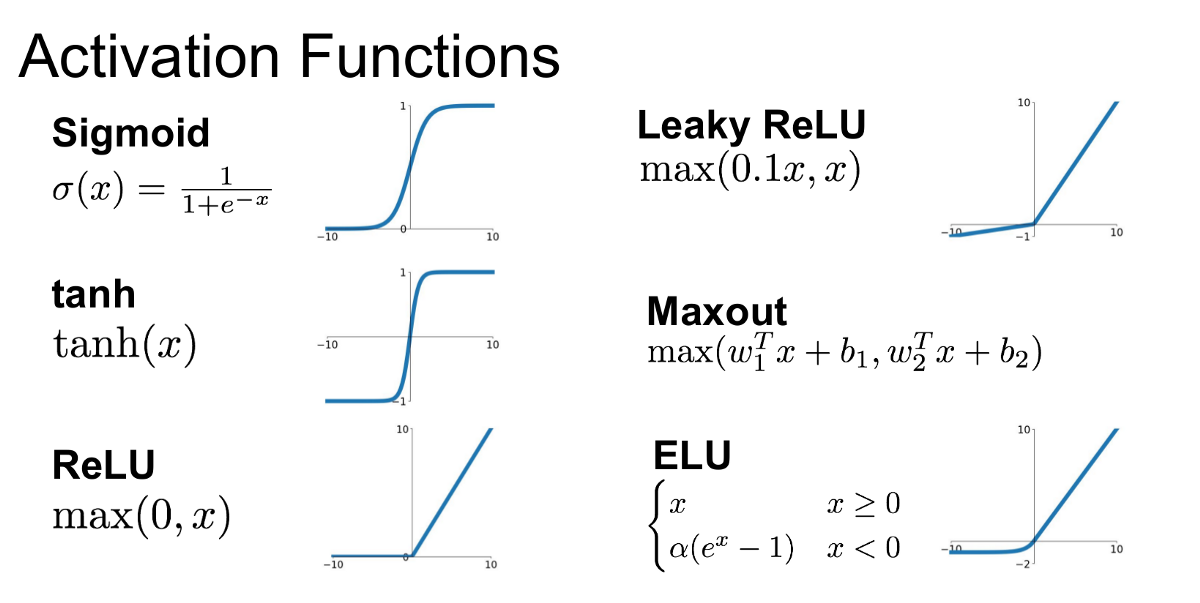
ReLU (Rectified Linear Unit)
- Sets negative values to zero, keeps positive values unchanged.
- Promotes sparsity in activations, focusing on relevant features.
- Computationally efficient and facilitates fast convergence during training.
- Limitations: Can suffer from dead neurons and unbounded activations in deeper networks.
Sigmoid
- Squashes activations between 0 and 1, suitable for binary classification tasks.
- Captures non-linearity within a limited range.
- Differentiable, enabling efficient backpropagation.
- Limitations: Susceptible to the vanishing gradient problem and may not be ideal for deep networks.
Tanh
- Maps activations to the range -1 to 1, capturing non-linearity within a bounded output.
- Has a steeper gradient than sigmoid, useful for learning complex representations.
- Facilitates better gradient flow during backpropagation.
- Limitations: Also faces the vanishing gradient problem.
Summary
Activation functions are crucial as they introduce non-linearity, enabling CNNs to model complex relationships and capture intricate patterns. Non-linearity allows CNNs to approximate complex functions and tackle tasks like image recognition and object detection. Understanding the properties and trade-offs of activation functions empowers informed choices in designing CNN architectures, leveraging their strengths to unlock the networks full expressive power.
By selecting appropriate activation functions, CNNs can learn rich representations and effectively handle challenging tasks, enhancing their overall performance and capabilities.